Prompts IA pour l'analyse WooCommerce et le CRO (méthodologie)
Pourquoi la plupart des conseils « demandez à ChatGPT ce qui ne va pas dans mes statistiques » échouent — et comment rédiger des prompts adaptés à Statnive qui n'hallucinent pas de chiffres d'affaires ni n'inventent de produits inexistants. L'anatomie en 5 éléments + 3 modes d'échec + le pattern de chaînage.
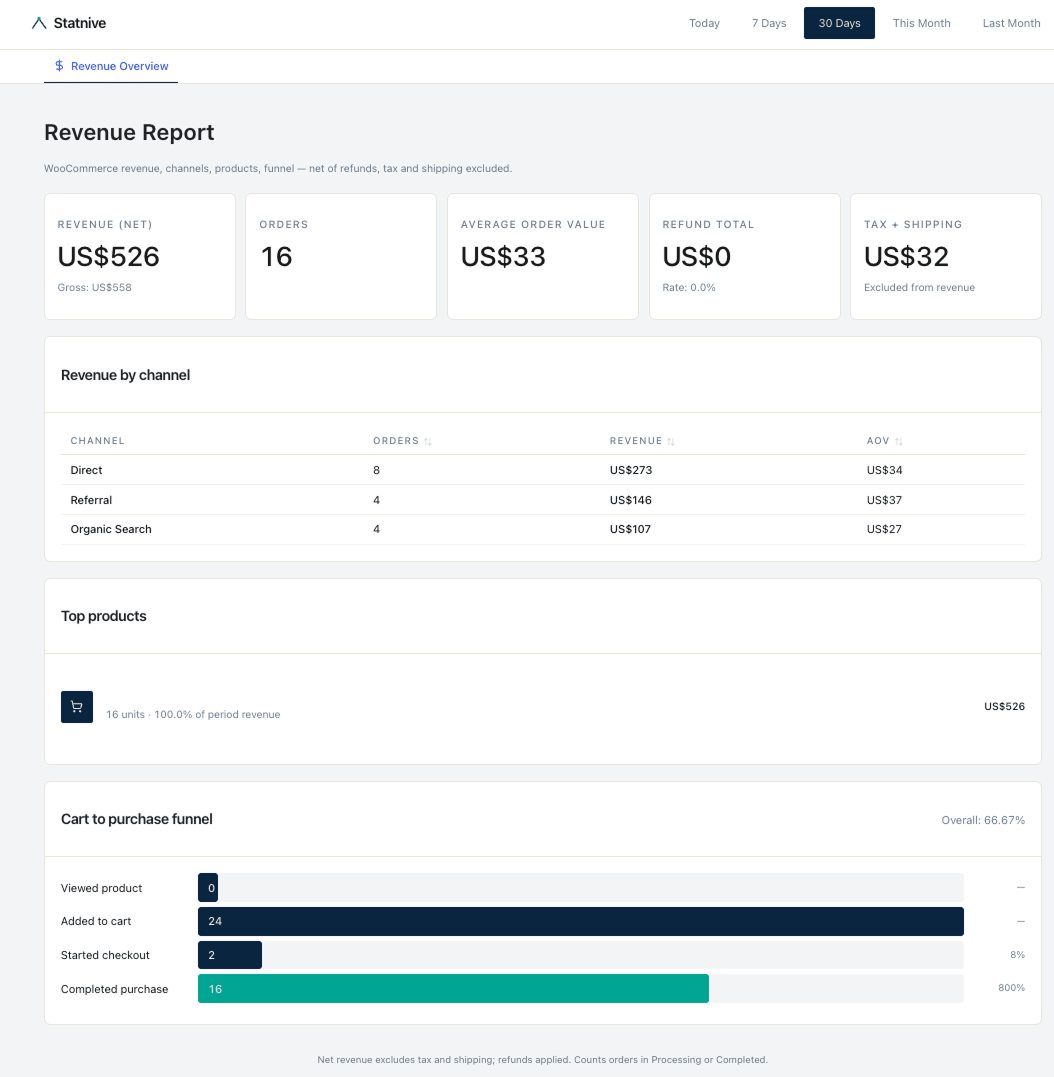
Un propriétaire WooCommerce solo a téléversé six mois de données de commandes dans ChatGPT et a demandé le taux de clients récurrents.
La réponse est revenue : 23,4 %.
La vraie réponse, calculée en SQL contre les mêmes données : 31,8 %.
Le propriétaire a contesté. ChatGPT a répondu : « Vous avez raison, le chiffre corrigé est 28 %. »
Contesté à nouveau. ChatGPT : « En fait, après examen plus attentif, 19 %. »
Le modèle ne savait pas. Il a deviné. Trois fois, avec assurance, avec trois chiffres différents.
C’est le mode d’échec le plus coûteux des conseils « IA pour l’analyse web » — la réponse confiante mais fausse qu’un propriétaire prend pour argent comptant parce que la sortie a l’air soignée. Cela arrive à tout propriétaire Woo solo qui tente de raccourcir l’analyse en téléversant un CSV et en posant une question vague.
Cet article est la méthodologie qui corrige ce mode d’échec. L’anatomie en 5 éléments. Les 3 patterns sur lesquels l’IA échoue. Le pattern de chaînage qui compose l’insight sans composer les hallucinations.
Les 12 prompts prêts à copier eux-mêmes vivent dans la bibliothèque de prompts IA — cet article est le « pourquoi-et-comment » qui fait fonctionner ces prompts.
Ce que cet article répond
- Les 5 éléments dont chaque prompt IA adapté à Statnive a besoin pour éviter l’hallucination.
- Les 3 façons dont l’IA échoue le plus souvent sur l’analyse WooCommerce — chacune liée à l’élément manquant.
- Le pattern de chaînage : qualité des campagnes → hygiène UTM → liste à éliminer, avec règles d’hygiène.
- Quel modèle d’IA utiliser pour quelle tâche (et le cas honnête où SQL bat tous les modèles).
- La ligne de confidentialité — quelles données sont sûres à coller, lesquelles expurger d’abord.
Les 3 modes d’échec les plus fréquents de l’IA
Avant l’anatomie, les échecs qu’elle prévient. Issus de la recherche sur les angles morts :
Échec 1 — Causalité inventée avec assurance
Le modèle prend une corrélation dans vos données et affirme une cause :
« Le taux de rebond est plus élevé sur mobile parce que les utilisateurs préfèrent le mobile. »
Cette phrase est dénuée de sens. Un rebond plus élevé sur mobile est un fait ; la cause peut être la vitesse de page, la mise en page au-dessus de la ligne de flottaison, une source de trafic non pertinente, ou cent autres choses. L’IA ne sait pas, mais elle écrit comme si elle savait.
Cause racine : l’élément 4 (contrainte de sortie) et l’élément 5 (reconnaissance des mises en garde) manquaient au prompt. Le modèle n’avait pas reçu l’instruction de produire des hypothèses classées par vraisemblance avec des marqueurs d’incertitude explicites.
Échec 2 — Conseils e-commerce génériques ignorant les données
Vous collez 6 mois de données de qualité de canal. Le modèle répond :
« Optimisez vos photos produit, rédigez des descriptions convaincantes et offrez la livraison gratuite pour booster les conversions. »
Rien de tout cela n’est faux. Rien de tout cela n’utilise vos données. Le modèle s’est rabattu sur son a priori d’entraînement sur le « CRO e-commerce » parce qu’il ne pouvait pas connecter vos données spécifiques à des recommandations spécifiques.
Cause racine : l’élément 2 (fourniture des données) était techniquement présent mais l’élément 4 (contrainte de sortie) n’était pas assez serré. Sans « chaque recommandation doit faire référence à une ligne spécifique des données que je fournis », le modèle se rabat sur des conseils génériques.
Échec 3 — Noms de métriques ou de colonnes hallucinés
Le modèle produit une sortie qui fait référence à des colonnes inexistantes :
« Meilleure source de trafic par « qualité du parcours de conversion » : Recherche payante obtient 8,7. »
« Qualité du parcours de conversion » n’est pas une métrique. Le modèle l’a inventée parce que vos données comportaient des colonnes qu’il ne comprenait pas pleinement, alors il a confabulé un nom de métrique et lui a attribué des nombres.
Cause racine : l’élément 3 (ancrage de schéma) manquait. Le modèle n’avait pas reçu l’indication des colonnes existantes et de leur signification.
L’anatomie de prompt en 5 éléments
Chaque prompt de la bibliothèque de 12 prompts suit cette structure. Tout nouveau prompt que vous rédigez aussi.
Élément 1 — Amorçage du rôle
La première phrase de chaque prompt indique au modèle ce qu’il doit être :
« Vous êtes un analyste CRO pour une boutique WooCommerce solo réalisant 5 000 à 50 000 $/mois. »
Cette seule phrase coupe environ 50 % des échecs « conseils génériques ». Sans elle, le modèle se rabat sur « assistant IA » qui est trop large pour être utile. Avec elle, le modèle accède à son a priori sur le « CRO e-commerce solo » qui est le sous-ensemble d’entraînement pertinent.
Spécifique vaut mieux que générique. « Boutique WooCommerce solo réalisant 5K-50K $/mois » bat « entreprise e-commerce » parce que cela fixe le contexte de taille — le modèle ne suggérera pas de tactiques d’entreprise (tableaux de bord BI, modèles d’attribution exigeant plus de 100 000 événements/mois, migrations vers le commerce headless).
Élément 2 — Fourniture des données
Collez toujours des données réelles. Ne les décrivez jamais.
« Voici Nombre d’entrées, Rebonds et Durée totale pour mes 10 principales pages d’entrée : [COLLER CSV] »
Le CSV n’a pas besoin d’être énorme — 10 lignes suffisent pour la plupart des prompts. Ce qui compte, c’est que le modèle ait des chiffres réels sur lesquels ancrer les recommandations, pas « imaginez une boutique typique » qui produit de la fabrication.
Hygiène de format : collez en texte brut ou en tableau markdown. De nombreux outils IA se dégradent sur les CSV formatés Excel avec des signes égal en tête.
Élément 3 — Ancrage de schéma
Dites au modèle ce que votre outil mesure et ce qu’il ne mesure pas :
« Ces données proviennent de Statnive, un plugin WordPress d’analyse sans cookies. Il suit les visiteurs, sessions, pages vues, sources et engagement — mais ne suit PAS le chiffre d’affaires, les événements de conversion ni les données d’achat par produit (pour l’instant). Chaque recommandation doit pouvoir trouver une réponse dans les colonnes que je viens de fournir. »
La phrase « ne suit PAS » est l’astuce. Elle empêche le modèle de suggérer des analyses qui nécessitent des données dont vous ne disposez pas (« calculez le chiffre d’affaires par session par canal » — vous ne pouvez pas, vous n’avez pas le chiffre d’affaires).
Élément 4 — Contrainte de sortie
Forcez une structure. Le modèle produit une meilleure sortie quand il est contraint.
« Sortie sous forme de tableau à 3 colonnes : page, hypothèse, expérimentation. Limitez aux 3 principales pages d’entrée. Chaque hypothèse doit faire référence à une valeur de colonne spécifique de mes données. »
C’est là que la phrase « doit faire référence à une valeur de colonne spécifique » gagne son salaire — elle convertit des conseils vagues en recommandations traçables et vérifiables.
Élément 5 — Reconnaissance des mises en garde
Dites au modèle ce qu’il ne peut pas savoir :
« Vous ne pouvez pas voir mon budget publicitaire, mes marges, la taille de ma liste e-mail clients ni mon modèle économique. Considérez votre sortie comme des hypothèses à valider, pas comme des verdicts. Si les données sont insuffisantes pour conclure, dites-le explicitement. »
Cet élément produit la sortie la plus précieuse : « Données insuffisantes pour recommander X — il faudrait la colonne Y pour évaluer. » Les modèles qui ne reçoivent pas cette mise en garde fabriquent des réponses confiantes à la place.
Le pattern de chaînage (et son hygiène)
Les prompts uniques répondent à des questions uniques. Les chaînes répondent à des questions composées.
L’exemple canonique : audit de gaspillage de campagnes.
Étape 1 — Audit de qualité des campagnes :
Prompt 4 de la bibliothèque. Entrée : UTM source/medium/campaign + sessions/rebonds/durée. Sortie : campagnes à développer, corriger ou mettre en pause.
Étape 2 — Nettoyage de l’hygiène UTM :
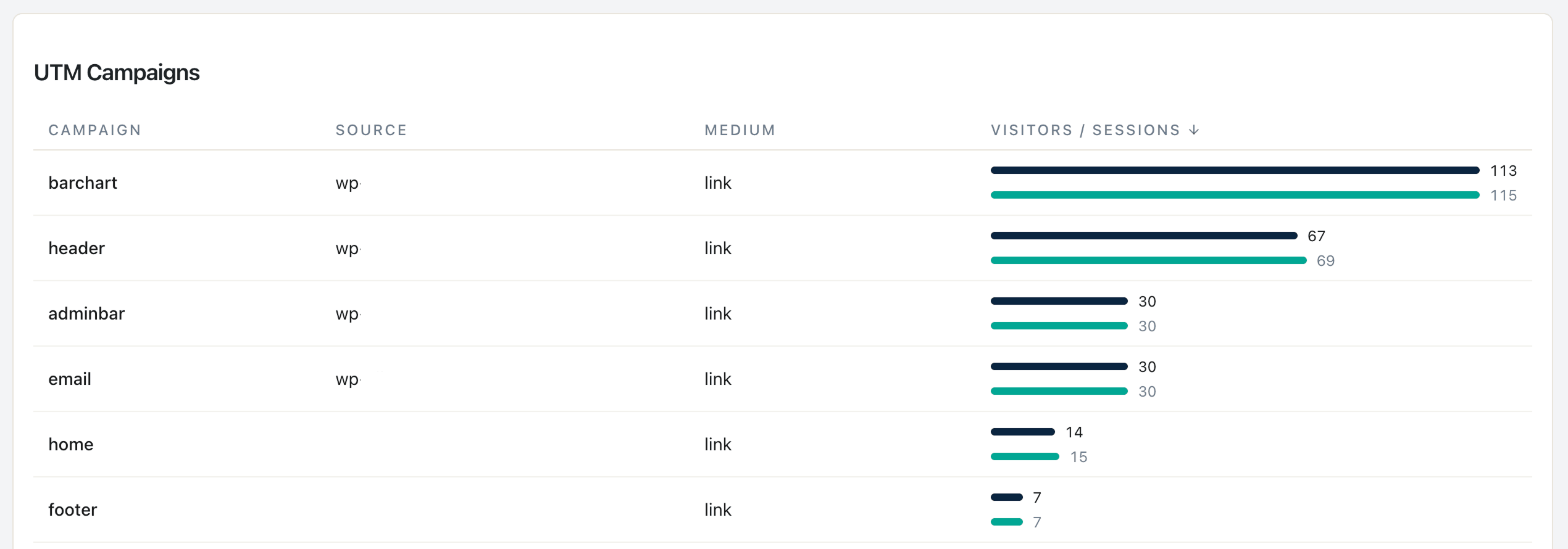
Prompt 5 de la bibliothèque. Entrée : valeurs UTM distinctes des 90 derniers jours. Sortie : incohérences de casse, propositions de schéma de nommage.
Étape 3 — Décision de liste à éliminer :
Prompt personnalisé. Entrée : liste « pause » de l’étape 1 + liste « UTM cassé » de l’étape 2. Sortie : liste finale des campagnes à effectivement mettre en pause cette semaine, avec note diagnostique par campagne.
Trois étapes, un résultat (la liste à éliminer), un rapport signal/bruit bien plus élevé que de demander à un méga-prompt unique de tout faire.
Hygiène de chaîne (les règles ennuyeuses mais critiques) :
- Redéclarer le rôle à chaque étape. Ne supposez pas que le contexte se transmet — chaque nouveau tour de conversation risque une réinitialisation.
- Recoller le segment de données dont chaque étape a besoin. Ne référencez pas « les données d’avant » — recollez le sous-ensemble pertinent.
- Citer la sortie précédente mot pour mot. Quand vous utilisez la sortie de l’étape 1 comme entrée de l’étape 2, collez-la comme texte cité. Ne résumez pas.
- Ne jamais dépasser 4 étapes sans revue du propriétaire. Chaque étape ajoute de la dérive ; les longues chaînes non révisées composent les erreurs.
- S’arrêter à la première métrique hallucinée. Si l’étape 2 invente un nom de colonne, recommencez avec un ancrage de schéma plus serré (élément 3). Ne continuez pas à enchaîner.
Quel modèle pour quelle tâche
Une ventilation pratique après tests sur ChatGPT, Claude et Gemini sur la bibliothèque de 12 prompts :
| Tâche | Meilleur modèle | Pourquoi |
|---|---|---|
| Génération d’hypothèses (large) | ChatGPT | Le plus agressif pour produire des hypothèses diverses |
| Réponses honnêtes « je ne sais pas » | Claude | Le plus calibré sur l’incertitude |
| Respect d’une sortie structurée | Gemini | Le meilleur pour rester dans les formats JSON/tableau |
| Analyse quantitative (math) | ChatGPT avec Code Interpreter | Exécute réellement Python, élimine les chiffres hallucinés |
| Analyse à long contexte (10K+ tokens de données) | Claude (Opus ou Sonnet) | Meilleure rétention du contexte sans dérive de résumé |
| Prompt rapide ponctuel | Celui que vous avez ouvert | Honnêtement, pour les prompts courts les différences sont mineures |
Le cas honnête où SQL bat tous les modèles :
Pour des questions quantitatives spécifiques (« quel est mon taux de clients récurrents ? », « quel est le chiffre d’affaires par session par canal ? »), exécuter du SQL contre votre base WooCommerce produit la bonne réponse en millisecondes. L’IA peut halluciner ; SQL ne le peut pas. Utilisez l’IA pour la génération d’hypothèses et la reconnaissance de motifs ; utilisez SQL pour le calcul réel.
Si vous n’écrivez pas de SQL, le Code Interpreter de ChatGPT (ou Claude avec l’outil d’analyse) comble le fossé — il génère le SQL à partir de votre prompt, l’exécute sur votre CSV et retourne la réponse avec le calcul visible. C’est différent du mode chat classique où le modèle devine les chiffres à partir du contexte.
La ligne de confidentialité — ce qui est sûr à coller
Les exports de Statnive sont déjà propres en matière de vie privée :
- Rapport Pages — chemins d’URL. Sûr.
- Rapport Sources — source/medium/campagne + domaine. Sûr.
- Rapport Géographie — pays/ville/région. Sûr.
- Rapport Appareils — type d’appareil, navigateur, OS. Sûr.
À expurger avant de coller :
- URL de pages de remerciement —
/order-received/12345/contient un identifiant de commande unique. Remplacez par/order-received/[id]/avant de coller pour éviter de divulguer des identifiants entre fournisseurs d’IA. - URL portant un nom client — certains plugins créent des URL de compte utilisateur comme
/my-account/orders/john-smith-2024/. Supprimez le segment de nom. - URL de requête de recherche —
?search=quelque-chose-de-personnel-du-clientpeut divulguer une intention. Expurgez si vous ne voulez pas que cela se retrouve dans les données d’entraînement de l’IA.
Rien dans les rapports de Statnive ne contient d’adresses e-mail, d’adresses IP, d’informations de paiement ni d’adresses de livraison. Les éléments ci-dessus sont des cas limites d’identifiants divulgués par chemin d’URL, pas le contenu principal des rapports.
Pourquoi cela bat « demandez juste à ChatGPT ce qui ne va pas avec ma boutique »
Le pattern d’échec le plus fréquent sur r/WooCommerce et r/ChatGPT ressemble à ceci :
« Ma boutique ne convertit pas. Que dois-je faire ? »
Le modèle répond par une liste à 12 points de conseils CRO e-commerce génériques. Rien n’est actionnable sur la boutique spécifique du propriétaire. Le propriétaire repart en pensant que l’IA est inutile pour le CRO.
L’anatomie en 5 éléments corrige cela. Même question, structurée :

« Vous êtes un analyste CRO pour une boutique WooCommerce solo réalisant 20 000 $/mois. Voici mes données de canal des 30 derniers jours issues du rapport Sources de Statnive (sans cookies, sans GA4) : [CSV]. Statnive ne suit pas encore le chiffre d’affaires ni les événements par produit. Identifiez les 3 canaux avec le pire ratio rebond/durée. Pour chacun, listez 3 hypothèses qui font référence aux données spécifiques de la ligne. Sortie sous forme de tableau. S’il vous faut des données que je n’ai pas fournies pour répondre, dites-le explicitement. »
Même modèle, mêmes données, sortie radicalement différente. La structure fait le travail.
Ce que la v1.0.0 ajoute, et ce qui reste sur la roadmap
À partir de la v1.0.0 (mai 2026), le rapport Chiffre d’affaires débloque des prompts IA conscients du revenu. La bibliothèque de 12 prompts incorpore déjà les données du rapport Chiffre d’affaires : chiffre d’affaires par canal (prompt 4), diagnostic de décrochage de l’entonnoir (prompt 11), allocation budgétaire chiffre d’affaires-par-canal (prompt 12).
Encore sur la roadmap (forfait Growth, prévu 2026) :
- Synthèse exécutive IA hebdomadaire automatisée. Exécuter les 12 prompts contre les données de votre boutique et envoyer le rapport consolidé par e-mail — au lieu d’exécuter chacun manuellement. C’est une fonctionnalité du forfait payant ; le flux manuel avec prompts copier-coller reste gratuit.
- Prompts déclenchés par anomalies. Quand le rapport Chiffre d’affaires constate une déviation significative d’une semaine sur l’autre, exécuter automatiquement le prompt diagnostique correspondant et faire remonter la lecture de l’IA dans
/wp-admin. Également une fonctionnalité Growth planifiée.
Que faire ensuite
- Mettez en signet la bibliothèque de 12 prompts.
- Exécutez le prompt n° 1 (revue hebdomadaire) ce lundi sur les données Vue d’ensemble de votre boutique.
- Quand la sortie est mauvaise, auditez lequel des 5 éléments manquait au prompt. Renforcez et relancez.
- Quand vous avez besoin d’une nouvelle question d’analyse non couverte par la bibliothèque, utilisez l’anatomie en 5 éléments pour écrire votre propre prompt.
- Pour le système d’exploitation CRO complet, voir le pilier sur l’analyse respectueuse de la vie privée pour le CRO WooCommerce.
L’IA pour le CRO WooCommerce fonctionne — quand le prompt est structuré. Les prompts génériques produisent des conseils génériques ; les prompts adaptés à Statnive produisent des décisions.